https://www.biaodianfu.com/hierarchical-clustering.html
K值确定
**法1:(轮廓系数)**在实际应用中,由于Kmean一般作为数据预处理,或者用于辅助分聚类贴标签。所以k一般不会设置很大。可以通过枚举,令k从2到一个固定值如10,在每个k值上重复运行数次kmeans(避免局部最优解),并计算当前k的平均轮廓系数,最后选取轮廓系数最大的值对应的k作为最终的集群数目。
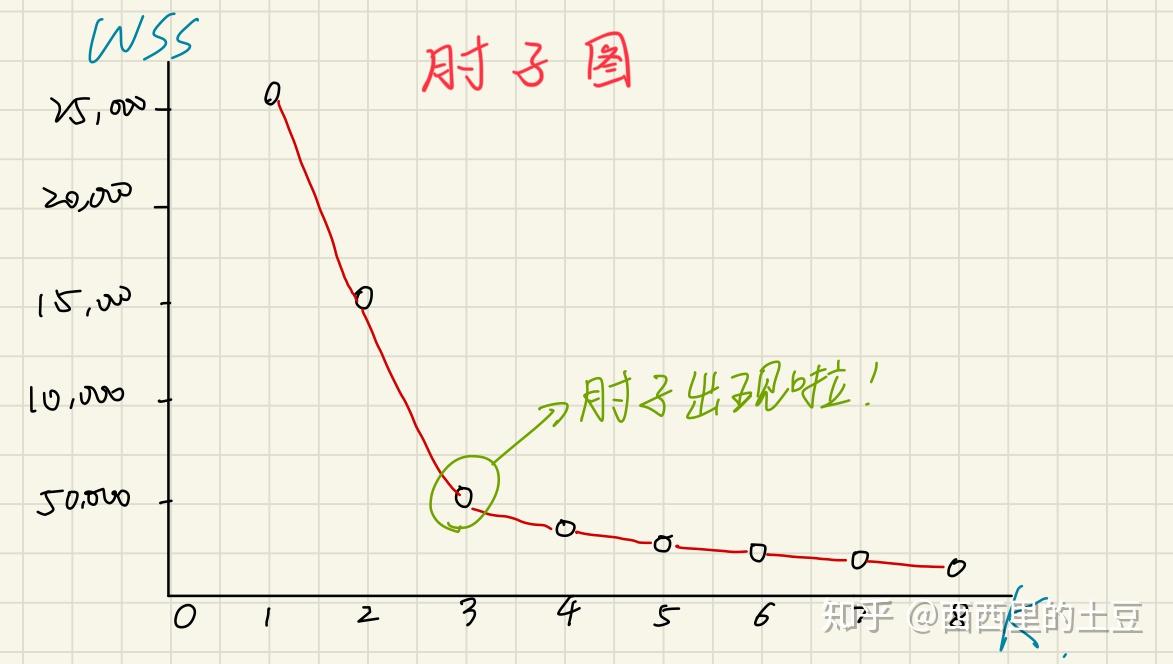
z常见的一种方法是elbow method,x轴为聚类的数量,y轴为WSS(within cluster sum of squares)也就是各个点到cluster中心的距离的平方的和。
法2:(Calinski-Harabasz准则)

其中SSB是类间方差,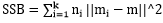 ,m为所有点的中心点,mi为某类的中心点;
,m为所有点的中心点,mi为某类的中心点;
SSW是类内方差,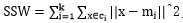 ;
;
(N-k)/(k-1)是复杂度;
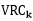 比率越大,数据分离度越大.
比率越大,数据分离度越大.
初始点选择方法:
思想,初始的聚类中心之间相互距离尽可能远.
法1(kmeans++):
1、从输入的数据点集合中随机选择一个点作为第一个聚类中心
2、对于数据集中的每一个点x,计算它与最近聚类中心(指已选择的聚类中心)的距离D(x)
3、选择一个新的数据点作为新的聚类中心,选择的原则是:D(x)较大的点,被选取作为聚类中心的概率较大
4、重复2和3直到k个聚类中心被选出来
5、利用这k个初始的聚类中心来运行标准的k-means算法
从上面的算法描述上可以看到,算法的关键是第3步,如何将D(x)反映到点被选择的概率上,一种算法如下:
1、先从我们的数据库随机挑个随机点当“种子点”
2、对于每个点,我们都计算其和最近的一个“种子点”的距离D(x)并保存在一个数组里,然后把这些距离加起来得到Sum(D(x))。
3、然后,再取一个随机值,用权重的方式来取计算下一个“种子点”。这个算法的实现是,先取一个能落在Sum(D(x))中的随机值Random,然后用Random -= D(x),直到其<=0,此时的点就是下一个“种子点”。
4、重复2和3直到k个聚类中心被选出来
5、利用这k个初始的聚类中心来运行标准的k-means算法
法2:选用层次聚类或Canopy算法进行初始聚类,然后从k个类别中分别随机选取k个点
,来作为kmeans的初始聚类中心点
优点:
1、 算法快速、简单;
2、 容易解释
3、 聚类效果中上
4、 适用于高维
缺陷:
1、 对离群点敏感,对噪声点和孤立点很敏感(通过k-centers算法可以解决)
2、 K-means算法中聚类个数k的初始化
3、初始聚类中心的选择,不同的初始点选择可能导致完全不同的聚类结果。